1Vermont Artificial Intelligence Lab, Department of Computer Science, University of Vermont
2Intelligent Machines Lab, Department of Artificial Intelligence, Information Technology University
3Institute of Artificial Intelligence, University of Central Florida
CVPR Findings 2026
Natural-language Guided Cross-view Geo-localization (NGCG) aims to retrieve geo-tagged satellite imagery using textual descriptions of ground scenes. While recent NGCG methods commonly rely on CLIP-style dual-encoder architectures, they often suffer from weak cross-modal generalization and require complex architectural designs. In contrast, Multimodal Large Language Models (MLLMs) offer powerful semantic reasoning capabilities but are not directly optimized for retrieval tasks. In this work, we present a simple yet effective framework to adapt MLLMs for NGCG via parameter-efficient finetuning. Our approach optimizes latent representations within the MLLM while preserving its pretrained multimodal knowledge, enabling strong cross-modal alignment without redesigning model architectures. Through systematic analysis of diverse variables, from model backbone to feature aggregation, we provide practical and generalizable insights for leveraging MLLMs in NGCG. Our method achieves SOTA on GeoText-1652 with a 12.2% improvement in Text-to-Image Recall@1 and secures top performance in 5 out of 12 subtasks on CVG-Text, all while surpassing baselines with far fewer trainable parameters. These results position MLLMs as a robust foundation for semantic cross-view retrieval and pave the way for MLLM-based NGCG to be adopted as a scalable, powerful alternative to traditional dual-encoder designs. Project page and code are available at https://yuqichen888.github.io/NGCG-MLLMs-web/.
⭐ How does the parameter scale of the MLLM backbones affect NGCG performance?
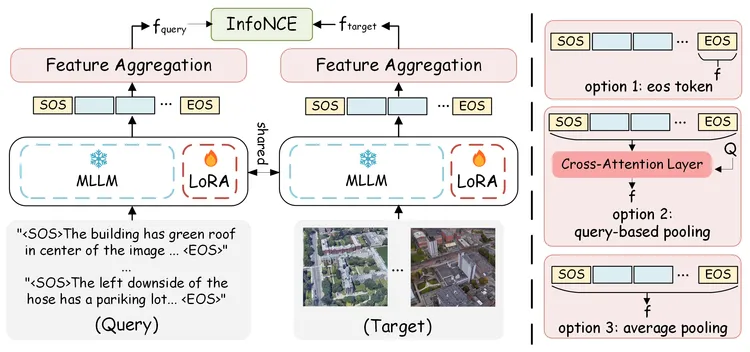
⭐ What is the best way to aggregate sequence embeddings to capture cross-view scene semantics?
⭐ Which tuning strategy is optimal? Specifically, Full Fine-Tuning (FFT) versus LoRA-based adaptation?
⭐ How do the hyperparameter configurations of the parameter-efficient module (e.g., LoRA) influence adaptation performance?
⭐ How do design choices within the contrastive learning objective influence the discriminative capability and stability of the learned embeddings?
⭐ We Explore MLLMs for the Natural-language Guided Cross-view Geo-localization (NGCG). We study an end-to-end parameter-efficient adaptation approach that preserves the conversation and reasoning ability of MLLMs, while enabling discriminative cross-modal retrieval.
⭐ We systematically explore key factors, including backbone scale, feature aggregation, and fine-tuning configurations. And we reveal practical insights and best practices for effectively adapting MLLMs to the NGCG task.
⭐ Our approach achieves a Recall@1 of 25.8% on GeoText-1652 and 5 best out of 12 subtasks on CVG-Text, outperforming prior NGCG methods and demonstrating the effectiveness of parameter-efficient MLLM adaptation.
